BPE Tokenizer: Training and Tokenization Explained

In my previous blog post, I explained in detail how large language models (LLMs) work, using analogies and maths. I received many requests for a simpler explanation of how a tokenizer is trained for such models, and how tokenization works. Hence, this blog post.
When you pass an input sequence (sentences, paragraphs, etc.) through a language model, a lot happens internally. For instance, when you ask an LLM, Where was Gautam Buddha born?, the first task it performs is splitting the text into tokens (words or subwords). These tokens are then converted into their corresponding ID numbers, called input IDs.
Why split into tokens, you might ask? It's because assigning a unique input ID to every possible word in the world is simply not feasible. For example, if GPT-2 has to understand the name Rabindra, it might split it into tokens like R, ab, ind, ra. This is because, with a vocabulary size limited to around 50k, the model cannot store every word as a whole. Just imagine there are over 200k words in the Oxford English Dictionary alone. And if we want the model to be multilingual, it becomes even more complex.
State-of-the-art models such as LLaMa 4 have a vocabulary size of 202,048, and DeepSeek has 129,280 — yet both are multilingual. This is why we need efficient tokenization algorithms that can break down words in a way that retains as much context as possible without missing important parts of the input sequence.
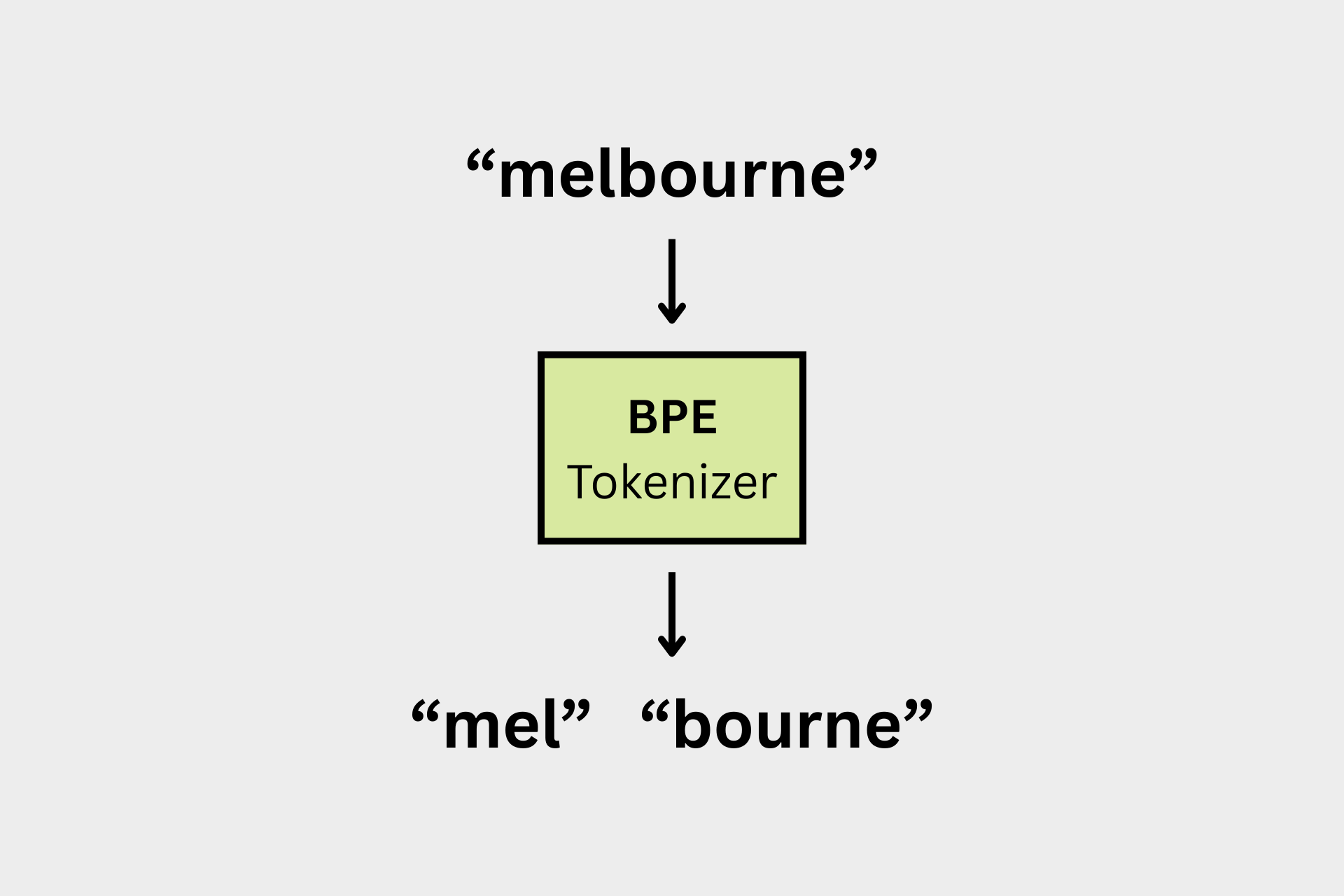
There are multiple tokenization algorithms. In this blog post, we are going to discuss one of the most popular: the BPE tokenizer. BPE stands for Byte Pair Encoding. Simply put, BPE is a tokenization algorithm that breaks words into smaller pieces based on frequency. This allows the model to handle rare or unseen words more effectively by merging frequent subwords. Practically, a tokenization algorithm is run on a large text corpus. For simplicity, in this blog, we’ll dive deep into how BPE works — step by step — using four simple words:
eat
eats
eating
eatenWe’ll cover:
- The complete training process of a BPE tokenizer
- How BPE tokenizes new input after training
Training a BPE Tokenizer
Our corpus has the following texts:
eat
eats
eating
eatenWe first add a special end-of-word symbol </w>:
eat</w>
eats</w>
eating</w>
eaten</w>Now, we split each word into characters:
e a t </w>
e a t s </w>
e a t i n g </w>
e a t e n </w>This becomes our initial corpus of symbol sequences.
Iteration 1
Let's do the first iteration of symbol counting. In the corpus above, we start by counting how many times the pair e and a appear together across the entire corpus. Then we move to the next pair, a and t, then t and </w>, and so on. We do this for all adjacent symbol pairs in the corpus.
Here's what we get from our first iteration:
symbol pair → frequency
e a → 4
a t → 4
t </w> → 1
t s → 1
s </w> → 1
t i → 1
i n → 1
n g → 1
g </w> → 1
t e → 1
e n → 1
n </w> → 1We know that e a and a t are the most frequent adjacent pairs. The idea is to merge the two symbols with the highest frequency in a single iteration. Since there are two adjacent pairs with the same highest frequency, we can choose either one. Let's go with the pair a t. Remember, merging e a would also have been a valid choice — we're just choosing a t for this example.
Let's also maintain a merge list and a vocabulary list. Since we’ve decided to merge a and t, let's start there.
merges: [{"a", "t"}]
vocabulary: [e, a, t, s, i, n, g, e, </w>, at]Note that we just added at into our vocabulary. The interesting thing with language models' tokenizers is that we can limit the size of the vocabulary. This is how we do it. We continue adding new merged symbols until we reach our vocabulary size.
With a and t merging decision, our corpus now becomes:
e at </w>
e at s </w>
e at i n g </w>
e at e n </w>Iteration 2
Now, we start again with our adjacent pairs and their frequencies.
symbol pair → frequency
e at → 4
at </w> → 1
at s → 1
s </w> → 1
at i → 1
i n → 1
n g → 1
g </w> → 1
at e → 1
e n → 1
n <w> → 1This time its a simple decision. Since e and at pair has the highest frequency, we merge them. Accordingly, we update the merge list and vocabulary list.
merges: [{"a", "t"}, {"e", "at"}]
vocabulary: [e, a, t, s, i, n, g, e, </w>, at, eat]At this stage, with the new merge rule, our corpus becomes:
eat </w>
eat s </w>
eat i n g </w>
eat e n </w>Iteration 3
Now let's go through another iteration:
symbol pair → frequency
eat </w> → 1
eat s → 1
s </w> → 1
eat i → 1
i n → 1
n g → 1
g </w> → 1
eat e → 1
e n → 1
n <w> → 1Okay, let's merge eat and s. This was where I wanted to make one thing clear. I did not merge eat and </w>, and there's a reason for it. </w> is just a symbol for marking a word's end. We keep this symbol while computing frequency but we do not merge it.
Now with this new merge decision, we update our merge list and vocabulary list:
merges: [{"a", "t"}, {"e", "at"}, {"eat", "s"}]
vocabulary: [e, a, t, s, i, n, g, e, </w>, at, eat, eats]After this, our corpus becomes something like this:
eat </w>
eats </w>
eat i n g </w>
eat e n </w>Iteration 4
We continue with the next iteration. Let's count adjacent pairs again:
symbol pair → frequency
eat </w> → 1
eats </w> → 1
eat i → 1
i n → 1
n g → 1
g </w> → 1
eat e → 1
e n → 1
n <w> → 1Let's now merge eat and i. With this merge, we update our merge and vocabulary list:
merges: [{"a", "t"}, {"e", "at"}, {"eat", "s"}, {"eat", "i"}]
vocabulary: [e, a, t, s, i, n, g, e, </w>, at, eat, eats, eati]... so on, we continue until no more merges are possible, or until we reach our vocabulary size.
- Iteration 5: merge
eatiandn - Iteration 6: merge
eatinandg - Iteration 7: merge
eatande - Iteration 8: merge
eateandn
Our final merges and vocabulary lists will look something like:
merges: [{"a", "t"}, {"e", "at"}, {"eat", "s"}, {"eat", "i"}, {"eati", "n"}, {"eatin", "g"}, {"eat", "e"}, {"eate", "n"}]
vocabulary: [e, a, t, s, i, n, g, e, </w>, at, eat, eats, eati, eatin, eating, eate, eaten]With this our tokenizer is now trained.
Now let's see how we use this trained tokenizer to tokenize new inputs.
Tokenization
Let's assume we want to process the word eating through our trained tokenizer. Just remember that the merging order is important. For e.g., our first merge rule is a and t to be merged. So we go with this merge at first. Even if two merges are possible, we stay with one at a time.
- Step 1: Our sequence is:
e a t i n g - Step 2: Match found:
a t→ merge toat - Step 3: Now our sequence becomes:
e at i n g - Step 4: Next, based on our merge rule, we can see that we can merge
eandat→ merge toeat - Step 5: And we go on.
Okay, now let's consider tokenizing a word that is not in the corpus, eated. Yeah, it is not even a word. This is just for an example.
Current sequence: e a t e d
- Apply
a tmerge:e at e d - Apply
e atmerge:eat e d - Apply
eat emerge:eate d
No more applicable merge in our list after eate d. This is how the word eated is tokenized into subwords eate and d.
Tokenizing a Long Sentence: When we provide a sentence to a trained tokenizer, words are split first and BPE is performed on each word independently, just like how we saw two examples earlier.
What If a Word is Totally Unknown? If a word or subword can't be built from the merges and vocabulary, it may be:
- Broken down into individual characters (kind of a fallback solution). With a larger corpus, the vocabulary will definitely have all characters.
- Replaced with an e.g.
<unk>token
Training a tiny tokenizer
Let's assume a tiny corpus with our four words and train a BPE tokenizer using the tokenizers library.
from tokenizers import Tokenizer, models, trainers, pre_tokenizers
# Define training corpus (our 4 words tiny corpus)
corpus = ["eat", "eats", "eating", "eaten"]
# Initialize a BPE model
tokenizer = Tokenizer(models.BPE())
# Define trainer
trainer = trainers.BpeTrainer(
vocab_size=20, # Small vocab since we have few words
special_tokens=["<unk>"]
)
# Train tokenizer on the tiny corpus
tokenizer.train_from_iterator(corpus, trainer)
# Save and view vocab/merges
print("Vocabulary:", tokenizer.get_vocab())
tokenizer.save("tiny_tokenizer.json")After the tokenizer is trained, we get the following merges and vocabulary.
"vocab": {
"<unk>": 0,
"a": 1,
"e": 2,
"g": 3,
"i": 4,
"n": 5,
"s": 6,
"t": 7,
"at": 8,
"eat": 9,
"en": 10,
"in": 11,
"eats": 12,
"eaten": 13,
"eatin": 14,
"eating": 15
},
"merges": [ [ "a", "t" ], [ "e", "at" ],
[ "e", "n" ], [ "i", "n" ],
[ "eat", "s" ], [ "eat", "en" ],
[ "eat", "in" ], [ "eatin", "g" ] ]
Content of tiny_tokenizer.json
You might have noticed input IDs assigned to each token in the vocabulary. Once tokenization is performed, the tokens are represented by their respective input IDs.
I think it is now clear what merges and vocabulary mean in the context of language model tokenizers. Different models might have slightly different ways of training tokenizers, but under the hood, BPE training and tokenization generally follow the same fundamental process, just like the step-by-step example we walked through.
Okay, that's it for today. I'll see you in the next one.
Further reading resources:
- Byte-pair encoding (Wikipedia)
- Pretrain MLMs (Using Langformers to train a tokenizer)