Pretrain Your Own RoBERTa model from Scratch

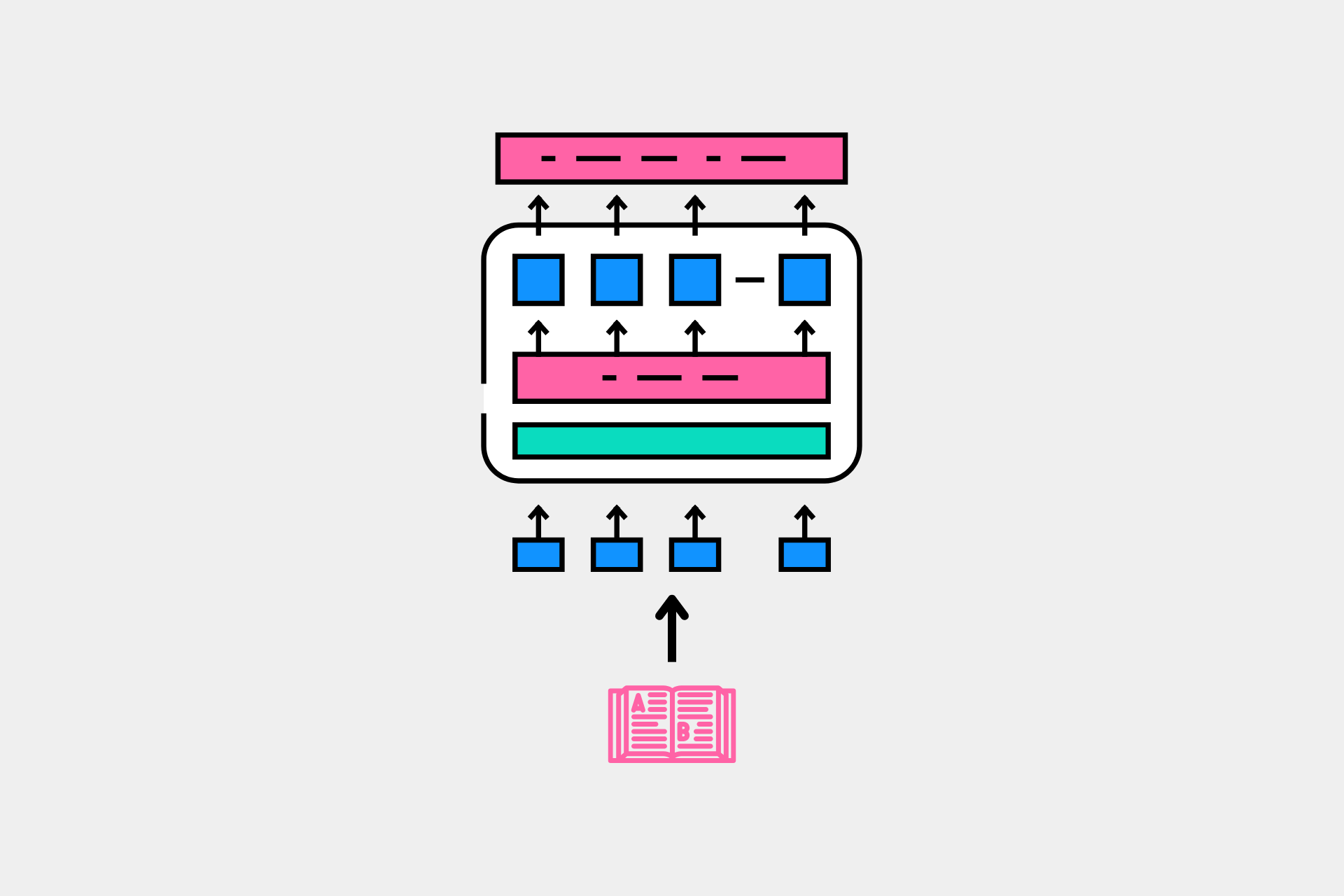
Masked Language Models (MLMs) like BERT, RoBERTa, and MPNet have revolutionized the way we understand and process language. These models are foundational for tasks such as text classification, named-entity recognition (NER), and many other NLP applications where the entire input sequence matters.
But what if you want to create your own MLM — tailored to your specific domain, like legal documents, medical texts, or tweets?
Langformers makes this process straightforward, flexible, and efficient!
In this guide, you'll learn how to pretrain an MLM from scratch with Langformers in just a few steps.
Why Pretrain Your Own MLM?
Pretraining an MLM is especially beneficial when:
- No existing domain-specific models fit your task (e.g., medical texts, legal papers, crisis communication).
- You want to continue pretraining an existing model like RoBERTa to better adapt it to your dataset.
- You aim to maximize performance on downstream tasks by aligning pretraining with your target data.
Examples of domain-specific MLMs include:
- BERTweet for tweets
- CrisisTransformers for crisis-related tweets
Overview of Pretraining Steps
There are three major steps to pretraining an MLM from scratch:
- Train a Tokenizer on your raw dataset and tokenize the dataset using the trained tokenizer.
- Train the MLM on the tokenized dataset.
Let’s dive into each step!
Setting Up
First, make sure you have Langformers installed in your environment. If not, install it using pip:
pip install -U langformers
Train a Tokenizer and Tokenize the Dataset
The first step is to build a tokenizer that can convert your raw text into a format the model understands. If you already have a tokenizer (like "roberta-base"), you can skip this step (as you'll only need to prepare a tokenized dataset). Otherwise, Langformers can help you train one easily.
# Import langformers
from langformers import tasks
# Define configuration for the tokenizer
tokenizer_config = {
"vocab_size": 50_265,
"min_frequency": 2,
"max_length": 512,
# ...
}
# Train the tokenizer and tokenize the dataset
tokenizer = tasks.create_tokenizer(data_path="data.txt", tokenizer_config=tokenizer_config)
tokenizer.train()After training:
- Your tokenizer will be saved inside a
"tokenizer"folder. - Your tokenized dataset will be saved inside a
"tokenized_dataset"folder.
Tip: Each line in your data.txt should contain a complete sentence or document.Simply, pass the path to an existing tokenizer if you do not want to create a new one. For instance, if you want to further pretrain roberta-base:
# Import Langformers
from langformers import tasks
# Tokenize the dataset with existing tokenizer.
# This example uses "roberta-base" tokenizer from Hugging Face.
dataset = tasks.create_tokenizer(data_path="data.txt", tokenizer="roberta-base")
dataset.train()Initialize the MLM Model and Define Training Configurations
Now that your dataset is tokenized, it's time to define the architecture of your MLM and set the training configurations.
Model architecture example:
# Define model architecture
model_config = {
"vocab_size": 50_265, # Size of the vocabulary (must match tokenizer's `vocab_size`)
"max_position_embeddings": 514, # !imp Maximum sequence length (tokenizer's `max_length` + 2)
"num_attention_heads": 12, # Number of attention heads
"num_hidden_layers": 12, # Number of hidden layers
"hidden_size": 768, # Size of the hidden layers
"intermediate_size": 3072, # Size of the intermediate layer in the Transformer
# ...
}Training configuration example:
# Define training configuration
training_config = {
"per_device_train_batch_size": 4, # Batch size during training (per device)
"num_train_epochs": 2, # Number of training epochs
"save_total_limit": 1, # Maximum number of checkpoints to save
"learning_rate": 2e-4, # Learning rate for optimization
# ...
}Train the MLM
Now you’re ready to train!
# Initialize the training
model = tasks.create_mlm(
tokenizer="/path/to/tokenizer",
tokenized_dataset="/path/to/tokenized_dataset",
training_config=training_config,
model_config=model_config
)
# Start the training
model.train()Langformers uses the RoBERTa pretraining procedure under the hood, ensuring a robust and efficient training process. Therefore, further pretraining is supported for models which have been trained with RoBERTa pretraining procedure.
Important Notes
- Tokenizer Vocabulary:
The model’svocab_sizemust match the tokenizer’s vocabulary size exactly. - Max Position Embeddings:
Set it totokenizer max_length + 2. (Example: 512 tokens → 514 max position embeddings.) - Checkpointing and Resuming:
You can also resume training from a checkpoint by passing thecheckpoint_pathparameter tocreate_mlm()instead ofmodel_config. - Learning Rate Adjustments:
It’s common during MLM training for the loss to suddenly spike.
If this happens:- Halve your current learning rate.
- Revert to the last stable checkpoint.
- Resume training by passing the
checkpoint_pathparameter tocreate_mlm().
Pro Tip: When working with large datasets or limited hardware, simulate a large batch size with gradient accumulation and multiple GPUs.
Final Thoughts
Pretraining your own MLM might sound intimidating at first, but with Langformers, it’s remarkably accessible. Whether you're building a model for a niche domain or advancing research on new tasks, training your MLM from scratch (or continuing pretraining) can significantly boost the performance and relevance of your NLP applications.
Ready to build your own domain-adapted BERT or RoBERTa?
Start today with Langformers! 🚀
View official documentation here: https://docs.langformers.com/pretrain-mlms.html