Sentence Embeddings & Similarity: Explained Simply


Have you ever wondered how computers understand that two sentences mean the same thing—or are similar—even if they don't use the same words?
Well, that's the magic of sentence embeddings and cosine similarity.
Let’s dive in, ditch the jargon, and keep it simple.
What are Sentence Embeddings?
Imagine you have a sentence:
Hey bro, I am visiting Rome tomorrrow.
Computers don't understand natural language the way humans do. They need numbers. So, we convert this sentence into a list of numbers (i.e., a vector). This vector captures the meaning of the sentence in numerical form.
This process is called embedding.
In machine learning and NLP literature, you'll often see terms like text representations or sentence embeddings. A sentence embedding is just a numerical representation of the full sentence that captures its meaning. It looks something like this:
[0.32, -0.19, 0.56, ..., 0.04] ← a vector with maybe 384 or 768 numbers
Once a sentence is represented as a vector like the one above, we can do all sorts of things with it.
The numbers 384 and 768 refer to the dimensionality of the vector. If a sentence is represented by a 768-dimensional vector, that means there are 768 numbers (components actually) to represent that sentence's meaning.
These vectors are learned by AI models. An example is Sentence Transformers. Such models are trained on millions, or even billions, of text samples to learn a vector space where the vectors of the following example sentences are close together:
- "Hey bro, I am visiting Rome tomorrow."
- "Hey mate, I am visiting Rome tomorrow."
- "Hey bro, I am visiting the capital of Italy tomorrow."
How do we Measure Similarity?
Once sentences are embedded (an NLP way of saying converted to vectors), we can measure how similar they are using something you may remember from school: Cosine of the angle between two vectors.
What is Cosine Similarity?
Suppose you have two vectors. Think of each vector as an arrow pointing in space. The angle between the two arrows tells us how similar they are.
- If the two arrows point in exactly the same direction, the angle is 0°, and cos(0) = 1 -> very similar.
- If the angle is 90°, cos(90) = 0 -> no similarity.
- If they point in opposite directions, cos(180) = -1 -> completely dissimilar.
You get the idea: the cosine of the angle between the vectors gives us the cosine similarity.
Here's the formula to compute cosine between two vectors:
\[ \text{cosine similarity} = \frac{A \cdot B}{\left\| A \right\| \times \left\| B \right\|} \]
Where:
- \( A \cdot B \) is the dot product of the two vectors
- \( \left\| A \right\| \text{and} \left\| B \right\| \) are magnitudes (length) of each vector
Intuition: Let’s say Harry and Gary are pointing at the sky. If both point to the same star, their arms are aligned. That’s angle = 0°, so cosine similarity = 1. If they point at different stars, the cosine similarity decreases, depending on how far apart their directions are.
In the world of sentence meaning (ideally):
- "I love pizza." and "Pizza is my favourite." -> cosine similarity ≈ 1
- "I love pizza." and "The weather is hot." -> cosine similarity ≈ 0
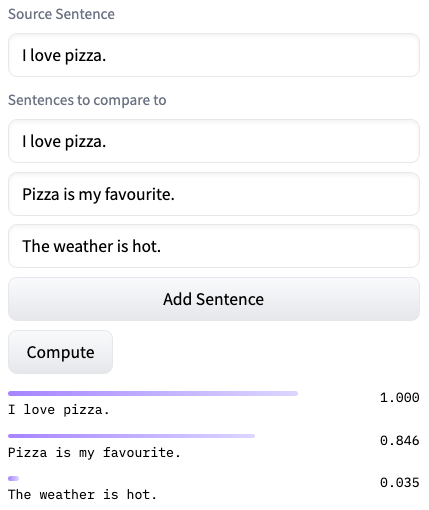
Sentence embedding with Langformers
Langformers makes it easy to get started with sentence embeddings—just 3 lines of code!
Make sure Langformers is installed:
pip install -U langformersNow import tasks from langformers, create an embedder, and run the embed method. In this example, we’ll use the "sentence-transformers/all-MiniLM-L6-v2" model from Hugging Face.
# Import langformers
from langformers import tasks
# Create an embedder
embedder = tasks.create_embedder(provider="huggingface", model_name="sentence-transformers/all-MiniLM-L6-v2")
# Get your sentence embeddings
embeddings = embedder.embed(["I am hungry.", "I want to eat something."])You can also compute the cosine similarity directly:
# Get cosine similarity
similarity_score = embedder.similarity(["I am hungry.", "I am starving."])
print(f"Similarity Score: {similarity_score}")For more details on sentence embeddings, check out the article: Sentence Embedding and Similarity with Langformers, or explore the Langformers documentation.
That's all for this one.
See you in the next!